인공지능응용시스템LS1
인하대학교 ICE4101 수업을 듣고 정리하였습니다.
잘못된 내용은 코멘트 부탁드립니다.
인공지능 응용시스템 Lecture Summary #1 12161783 전민규
Machine Learning Basics
ML Overview
Supervised Learning : 정답(label)을 제공하면서 학습 시키고 문제를 해결하는 방법을 제공하면서 학습 시키고 문제를 해결하는 방법 ⇒ 본 강의는 주로 이내용을 다룸
Regression : 데이터의 추정치를 근사하는 식을 만드는 것 ⇒ x,y좌표를 받아 차량의 heading값을 구할 수 있는 프로젝트를 해볼까? **
Classification : 데이터를 구분하는 식을 만드는 것
- Unsupervised Learning : 정답(label)을 제공하지 않고 경향성을 찾도록 하는 방법
- Reinforcement Learning : supervised와 Unsupervised를 환경에 따라 적절하게 사용하느것
Machine Learning : 사람이 관여한 학습
Deep Learning : 전면 자동 학습
Model Parameters : 학습결과
HyperParameters : 유저가 설정한 값 ex)모델 사이즈
- Data Split for ML : 처음에 data를 train data와 test data를 나누고 나서 train data 또한 모의고사용으로 validation을 따로 주어야 테스트전에 평향되지 않은 결과로 검증된 test할 수 있다.
Linear Regression
정의역 x를 입력으로 주면 y를 알 수 있음
⇒ 확장한 Linear Prediction ( 여러차원의 input )
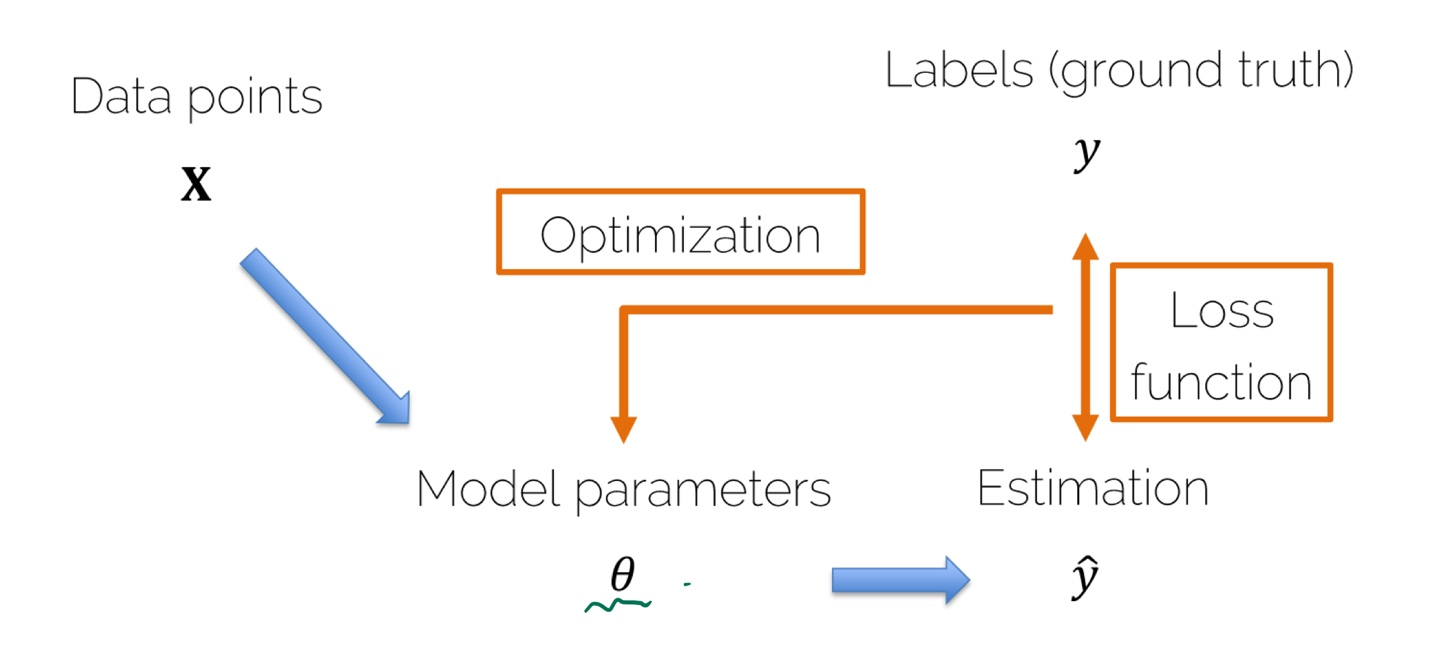
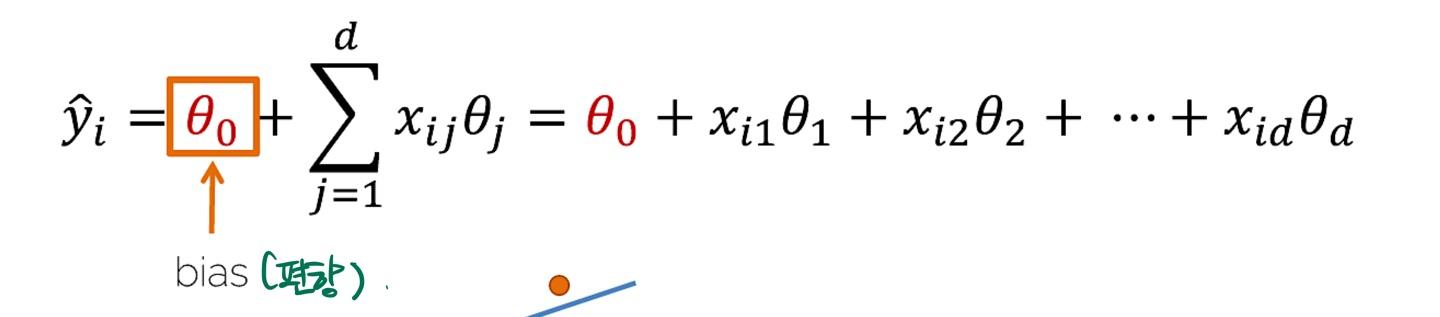
- Loss function(손실 함수) : 예상값과 실제값과의 차이를 함수로 정의 한 것
- Optimization : 손실 함수를 줄일 수 있게 Model parameters에 피드백을 주는 행동
Nearest Neighbors
⇒ test시 가장 거리가 가까운 label의 class로 판단
Image Classification : 이미지를 주면 이게 무엇인지 보는 것
⇒Semantic Gap,viewpoint variation, Background Clutter, illumination. Occlusion. Intar-class variation, Inter-class variation 등의 이슈가 있다.
Intra-class variation VS Inter-class variation
클래스 내의 분포 VS 클래스 간의 거리 ⇒작을 수록 ⇒ 멀수록 좋다. (구분감)
Distance Metric : 거리계산 공식 ex) L1 , L2
⇒ L1은 Mangattan 거리로 x와 y의 합을 구한 거리이고 L2는 Euclidean 거리로 x와 y따로 구하지않고 제곱한 거리이다.(선호)
Nearest Neighbors 특징
모든 data를 기억하고 test시 비교해서 결과를 내므로 training은 빠를 수 있으나 기억해야하는 data도 많고 test시 시간이 오래걸린다. 또한 어떠한 사람이 봤을때 항상 구분이 가능하나 이것은 구분을 못할 수 있다. (인위적으로 한부분 가린경우)
Dimensionality Reduction/Expansion
- Dimension Expansion ⇒ 클래스 내의 분포와 거리가 애매해서 구분이 어려운 경우 사용
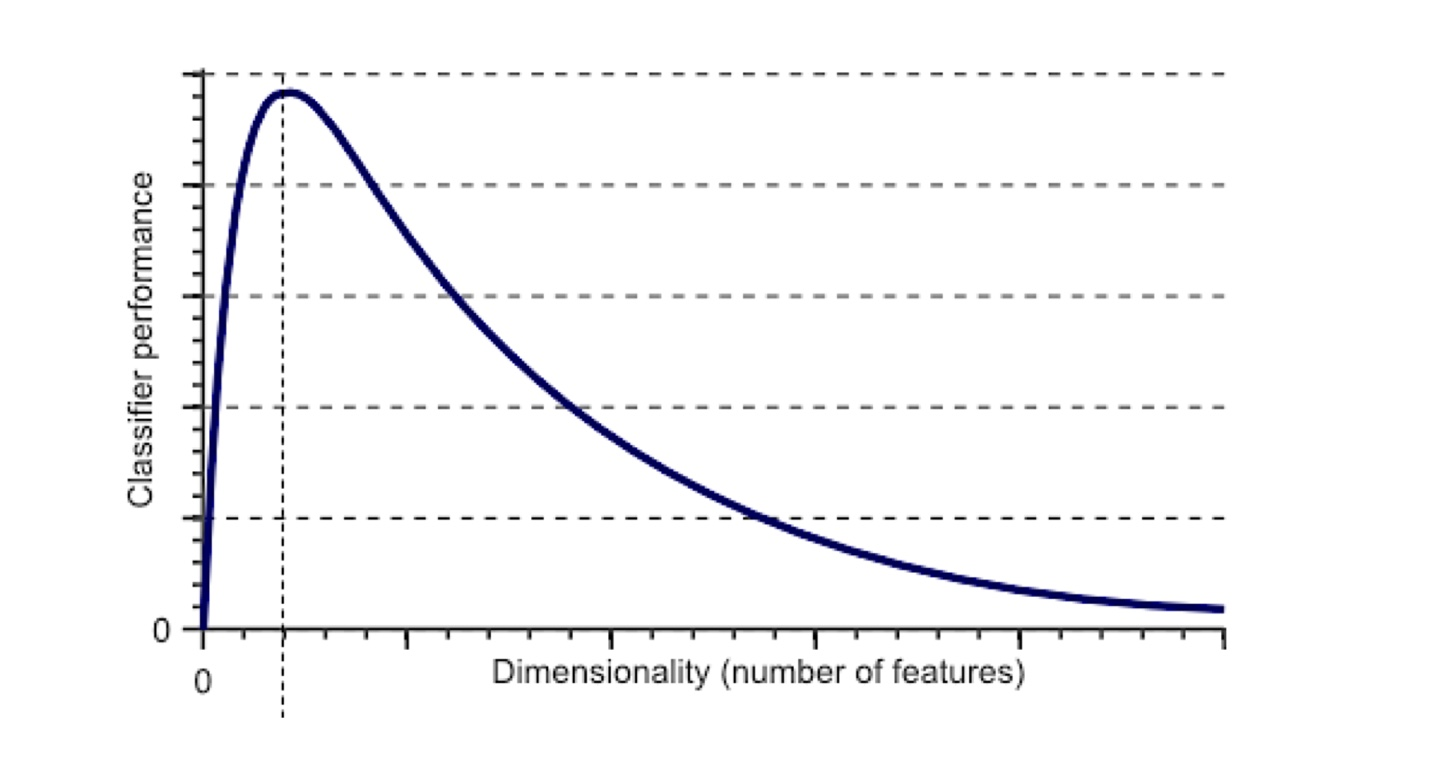
Dimension을 확장하여 classifier performance를 증가 시킬 수 있으나, 과하게 확장시 감소한다. 즉, 적당한 Dimenstion Expansion을 해야함.
Dimension Reduction
PCA : 최적의 표현을 할 수 있는 최대 분산을 찾도록 차원을 축소하는것
LDA : 클래스의 구분감을 올리기 위해 차원을 축소하는것
t-sne: 시각화를 위해 차원을 축소하는것
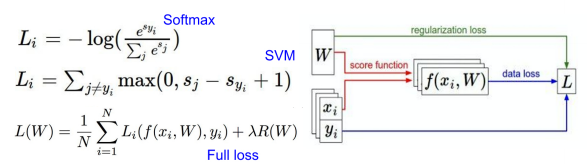
Linear Classifier
: W(weights)를 조정하여 label class의 score를 증가시켜 Classifier를 수행함
input x→ f(x,W) → Class scores 이 때 Class scores 들을 이용하여 정답 scores와 비교를 통한 다양한 Loss Function을 줄여 Weight를 조정한다. (Optimization)
- nonlinear한 경우 Layer 사이에 Nonlinearity activation function을 더해서 해결한다. ( 이것은 뒤에 Deep Neural Network의 기본이 됨) ⇒ W1*W2 (선형적인) 해도 Linear이다.
SVM classifier vs Softmax Classifer
⇒ Loss function (손실함수) 비교
SVM Loss function(hinge loss)
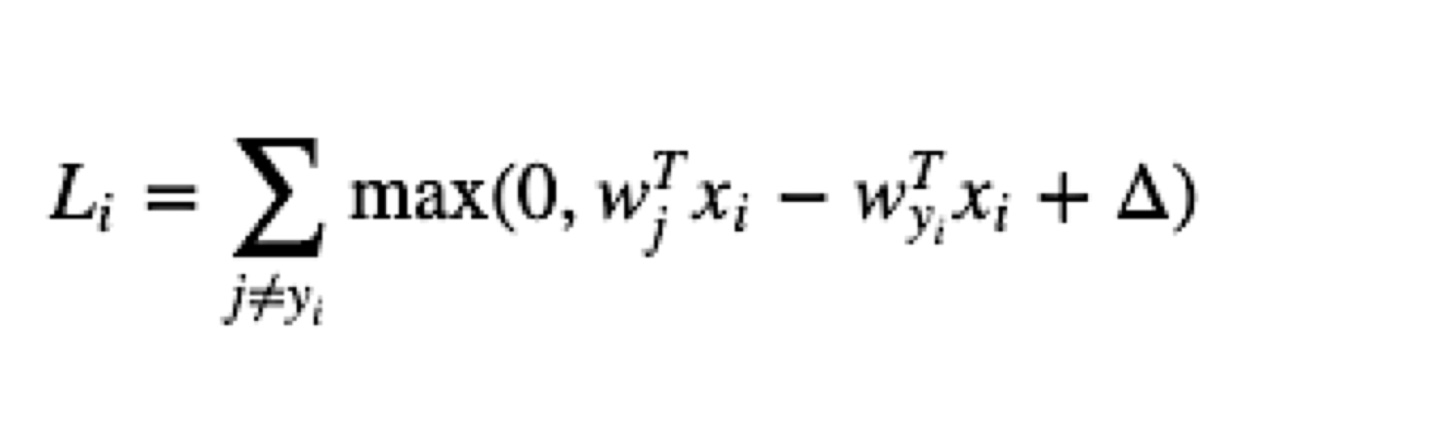
⇒margin 값만 넘기면 학습 종료하므로 상대적으로 욕심이 적다.
Softmax Loss function(Cross-Entropy Loss) ⇒확률이 합이 1이라는 성질을 다중 분류에 사용 (Multi-class classification에 주로 사용됨)
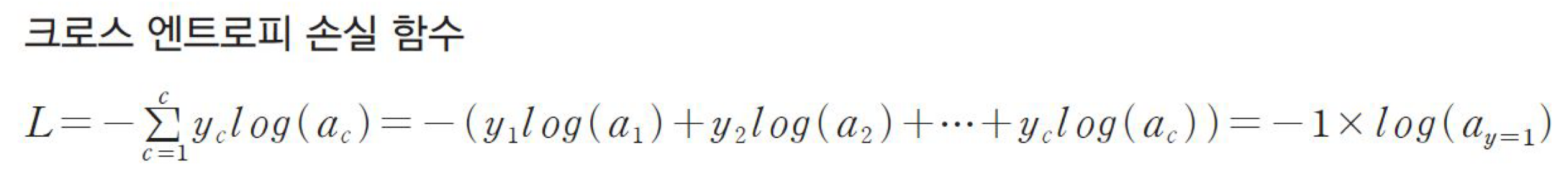
정확한 예측을 할 수록 L의 크기는 작아진다. 그러나 예측을 잘 못할수록 L이 커짐 이를 이용하여 loss함수를 최소화 시키는 방향으로 weight를 업데이트
⇒ corrct class score가 1.00이 되어야 학습을 종료하므로 상대적으로 욕심이 많다.
(추가) MSE(mean squared error) : regression(회귀) 용도의 딥러닝 모델을 훈련할 때 사용되는 손실 함수
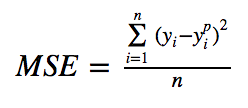
Object Detector인 Yolov4 모델의 Loss function인 Focal loss
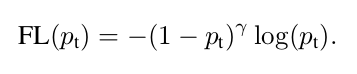
⇒ 예측을 잘 한 class에 대해서는 loss를 적게 해 loss갱신을 거의 못하게하고, 예측을 제대로 하지 못한 class에 대해서는 loss를 크게 줌
Neural Networks 1
Introduction to Neural Networks
인간의 Neural을 모방한 Networks
- n-layer-Neural Network linear score function에서 확장하여 Activation function (ex ReLu(max(0,x))) 를 이용하여 구성됨
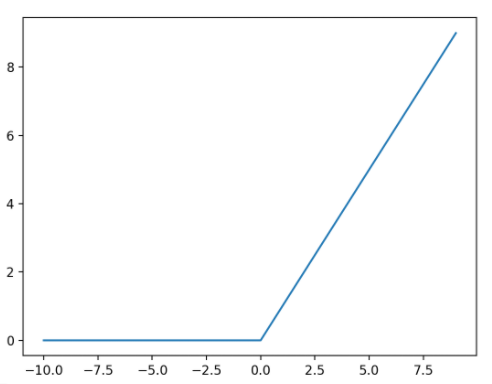
ReLu(활성함수)
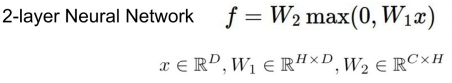
Gradient Descent
⇒ 최선의 W를 구하는 방법이 무엇일까? ( 랜덤하게 업데이트하게되도 생각보다 괜찮은 결과가 나온다 그러나 기울기를 따라 진행해보면 어떨까? 에서시작 )
gradient을 통해서 변화량을 구하고 0이 되는 방향으로 W를 조정
- Analytic Gradient : 편미분을 통하여 빠르고 정확하게 계산
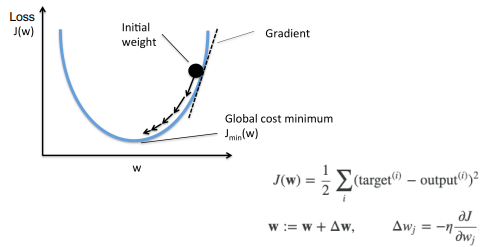
Computational Graph & Backpropagation
⇒ 계산이 복잡해지면 Loss에 대해서 gradient를 구하기 어려울 수 있다.
- Computational Graph : 연산을 그래프화
Backpropagation(역전파) : 미분을 통해 맨 뒤에서 부터 거꾸로 전파하여 W와 Bias를 조정
Regularization
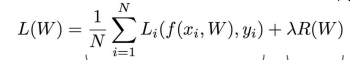

Regularization loss / R(W) : overfiting을 예방하기 위한 것 ( test에 맞추기 위한건데 너무 train에 맞춰지면 안됨)
Loss는 앞서구한 data loss와 Regularization loss를 더해서 구한다. ⇒ L2를 대부분 사용
Neural Networks 2
Data Preprocessing
Optimization 를 효율적으로 하기위해 전처리 하는과정
- zero-centered data : 영점조절 (기본)
- normalized data : 축 scale조절
- decorrelated data : 각 축에 직교하게 만듬 ( correlation을 없앰)
- whitened data : 축에 대해서 분산량이 동일하게 원의 형태로 만듬
⇒PCA 와 wthiening은 deep learning 에서 잘안쓴다
Weight Initialization
NN 요약 : input layer→ Hidden layer (W) →Ouput layer : 사이사이는 nonlinear이지만 마지막은 linear!
( Not guaranteed to reach the optimum, 기울기가 0이라고 optimum이라고 하면안됨)
- Global Optimum: 결론적으로 원하는 값
- Local Minimum : non-convex할때 생긴 지점
W가 작은값으로 초기값을 갖게 될때 문제가 생김 (Activation function을 tanh로 사용할 때 ) ⇒ Layer를 통과시킬수록 가운데에 몰리기때문에 gradient도 작아지므로 업데이트가 발생하지 않음
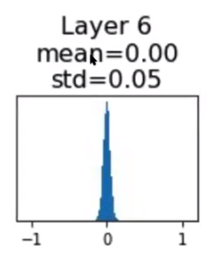
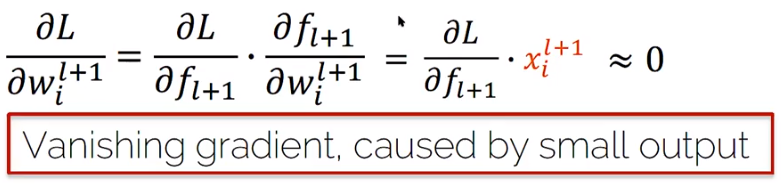
W가 상대적으로 큰경우 (tanh) ⇒ 마찬가지로 기울기가 0 이되므로 문제가 생김 ( 사이드로 과포화 )
- Xavier Initialization : 위의 문제를 해결하는 방법 표준 정규 분포를 입력 차원의 수로 스케일링 ⇒ ReLu 사용시 0신호가 가까워 지므로 2를 추가로 곱해주는 Kalming / MSRA Initialization 함Xavier Initialization : 위의 문제를 해결하는 방법 표준 정규 분포를 입력 차원의 수로 스케일링 ⇒ ReLu 사용시 0신호가 가까워 지므로 2를 추가로 곱해주는 Kalming / MSRA Initialization 함
Stocahstic Gradient Descent
데이터를 랜덤하게 샘플링 → traing → 다시 랜덤하게 샘플링 → traing → 반복
(통계적인 측면에서 좋은 성질을 이용)
- Batch : 수행 할 수 있는 범위 내에서 분활한 subset
- Epoch : 하나의 전체 데이터셋을 한바퀴 도는 것의 단위
- Iteration : Epoch을 도는데 필요한 Batch 수
(Fancier) Optimizers
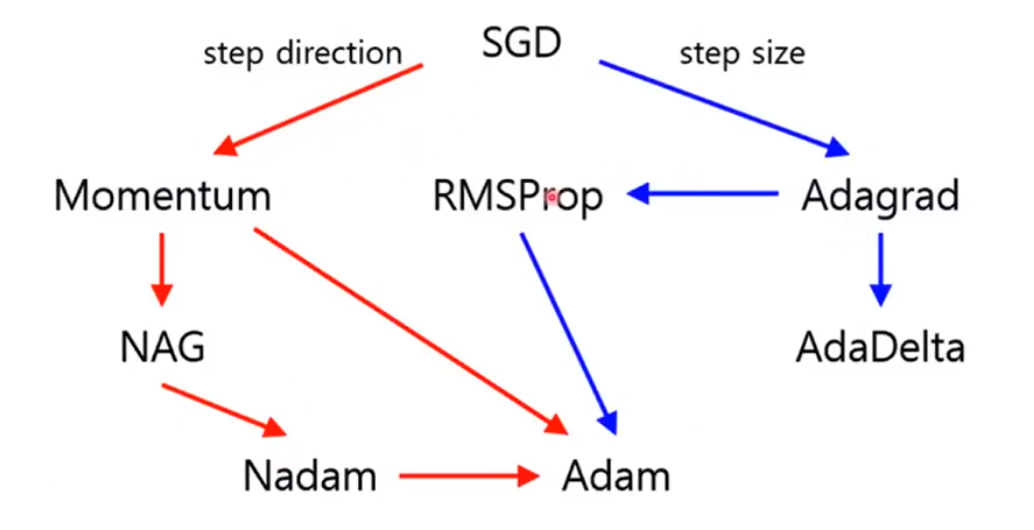
⇒ SGD도 Optimizers의 하나의 예지만, 문제가있다. 시간이 오래걸리거나 , Local minimum에 갖힐 수 있다.
- SGD + Momentum : velocity도 고려하여 gradient와 velocity의 벡터 합을 통해 실제 변화량을 계산하여 gradient이 0인 점에 갖히지 않도록함
- AdaGrad : gradient가 급격한경우 완만하게, 완만한경우 급격하게 변화 (제곱 이용)
- Adam : Momentum + AdaGrad (보통 이걸써라, SGD는 튜닝하기 어려울수 있음)
Regularization
- Overfitting : 학습할수록 train Accuract는 올라가나 val Accuract는 잘 올라가지 않을 때 ⇒더 많은 data 수집, regularization 규제, dropout 등과 같은 방법으로 Overfitting을 막을 수 잇음
- Underfitting : 학습후 train과 val의 Accuract차이는 크지않으나 실제test에서 낮은 Accuract를 나타낼 때 ⇒epochs횟수 늘리기, parameter가 더 많은 복잡한 모델 선택, model의 규제를 줄이는 방법 등으로 막을 수 있음
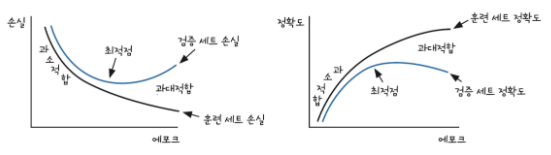
- Model Ensembles : 과대적합 시 사용하는 트릭 중 하나로 학습시 모델을 살짝 변화시킨 여러 모델들을 학습시키고 결과 확률의 평균중 최대값을 사용한다. 너무많은 학습량을 필요로 하므로 개인 레벨에서는 부적합하다.
- Regularization loss (Weight decay)
Dropout : 일정 확률로 노드 연결을 끊어 feature간의 연결성을 낮추고(co-adaptation) 분별력을 높임, Ensembles의 효과를 낼 수 있음
Dropout의 test time에는 모든 노드를 키고 score값에 노드의 확률을 곱하여 계산함
⇒ 학습시에는 p른 나눠줌 ( Inverted dropout )
- Data Augmentation : data를 실제 상황에서 일어날 수 있을 법한 변형을 적용 ex) Horizontal Flips (좌우대칭) , 상하대칭은 사용X(실제 잘 안일어남) Random crops and scales (랜덤하게 patch를 잘라냄) Color Jitter (픽셀 밝기나 contrast를 조절) …
- DropConnect : 노드는 살리고 Weight를 끊는 방법
- CutOut : 이미지 내에서 ramdom영역을 지워 학습
- Mixup : 랜덤으로 다른 두 class를 blend한 이미지를 목표label score을 blend 비율로 나누어서 학습
- Cutmix : CutOut+Mixup
⇒ 여러가지 짬봉하는 기법이나 실제 있을법한 환경으로 학습을 다양하게 해보자
Hyperparameter Tuning
: 성능을 최적화하거나, bias과 variance사이의 균형을 맞출 때, 알고리즘을 조절하기 위해 사용. 학습 전에 미리 지정되어 훈련하는 동안은 상수로 남게 되며, 가중치와 같은 파라미터와 다르게 주로 알고리즘 사용자에 의해 정해짐 → 과소적합, 과대적합을 피하기 위해 적당한 값이 설정
- Hyperparameter searching Random Search VS Grid Search : Ramdom이 최적 구간을 잘 잡을 수 있음 주로 사용Coarse to Fine : Random Search를 할때 모든 구간을 Search하지 않고 lough하게 진행하고 결과가 좋은 일정 구간을 search함
- Choosing Hyperparameters Guidelines step1. Check inital loss : 초기에 과대적합을 고민할 필요 없으므로 regulaization loss(weight decay)를 끄고 data loss만 사용 step2. Overfit a small sample : 학습데이터에 대해서 조금만 샘플링 후 경향성을 분석 step3. Find Learning Rate that makes loss go down : 전체 data에 대해 loss가 감소하는 learning rate 찾고 난 후 regulaization loss 고려함 step4. Coarse grid, train for ~1-5 epochs : coarse하게 몇개의 value를 찾고 step5. Refine grid, tarin longer : 확인 후 가장 성능 좋은 모델의 하이퍼파라미터로 부터 grid를 refine. step6. Look at loss curves : loss와 Accuracy를 분석 (경향성 분석) step7. setp4로 돌아가 반복
