인공지능응용시스템LS2
인하대학교 ICE4101 수업을 듣고 정리하였습니다.
잘못된 내용은 코멘트 부탁드립니다.
인공지능 응용시스템 Lecture Summary #2 12161783 전민규
Deep learning programming
Deep learning programming에 사용되는 플랫폼중 하드웨어는 병렬처리가 가능한 GPU가 핵심이고, 딥러닝에 필요한 연산, 기능들을 함수와 같이 구현한 프레임워크들을 활용하여 보다쉽게 DL programming을 할 수 있다.
Convolutional Neural Networks
이전에 학습한 Neural Networks의 기본적인 틀은 weights를 조절하여 loss를 줄이는 방식으로 구현되는 Network 이다. 이때 기본적인 Neural Networks는 data의 관계 정보는 이용하지 않게 된다. 예를 들어 classification에서 픽셀의 밝기값을 그대로 하나씩 늘려 사용하였기 때문에 가까이 있는 픽셀에 대해서 정보를 이용하지 않았기 때문에 효율적이지 못하였다.
이에 반해 CNN은 가까이 있는 픽셀에 대한 정보 즉, 공간의 정보를 활용한 Network이다. NN과 마찬가지로 weight를 조절하여 loss를 줄이는데 이때 weight는 2차원 벡터가 된다.
CNN은 원래 존재하였으나 각광받지 못하다가 AlexNet이라는 모델의 등장으로 각광받기 시작됐으며 이것은 최근 딥러닝 부흥의 시작점이되었다.
공간에서의 정보를 이용하기 때문에 모든픽셀마다 weight가 존재해야 하는 기본적인 NN과 달리 공간상의 정보를 이용하기 때문에 weight를 획기적으로 줄일 수 있다. CNN은 Convolution 연산을 기본적으로 수행하며 pooling과 같은 트릭을 이용하기도 한다.
Pooling은 data의 크기를 줄여 연산량을 줄이고 메모리를 아낄수 있기만 하는줄 알았는데 이것은 학습시 오버피팅되는 것을 방지할 수도 있었다. 즉, pooling시 정보의 손실이 생기지만 이것은 손실이아니라 오버피팅을 방지할 수 있는 트릭이 될 수도 있는것이다.
- Fully Connected Networks (FC layer) : 1x1 convolution layer로 마지막에
AlexNet은 ILSVRC에서 최초로 우승한 CNN모델이였다. AlexNet을 보면 Layer의 구성이 규칙적이지 않을 것을 알 수 있었는데 이것은 실험적인 결과로 좋은 성능을 낸 Layer의 구성이기 때문이다. 따라서 Deep Learning은 이론적인것 뿐만아니라 실험적으로 받아들여야 하는 부분도 중요하다고 할 수 있다.
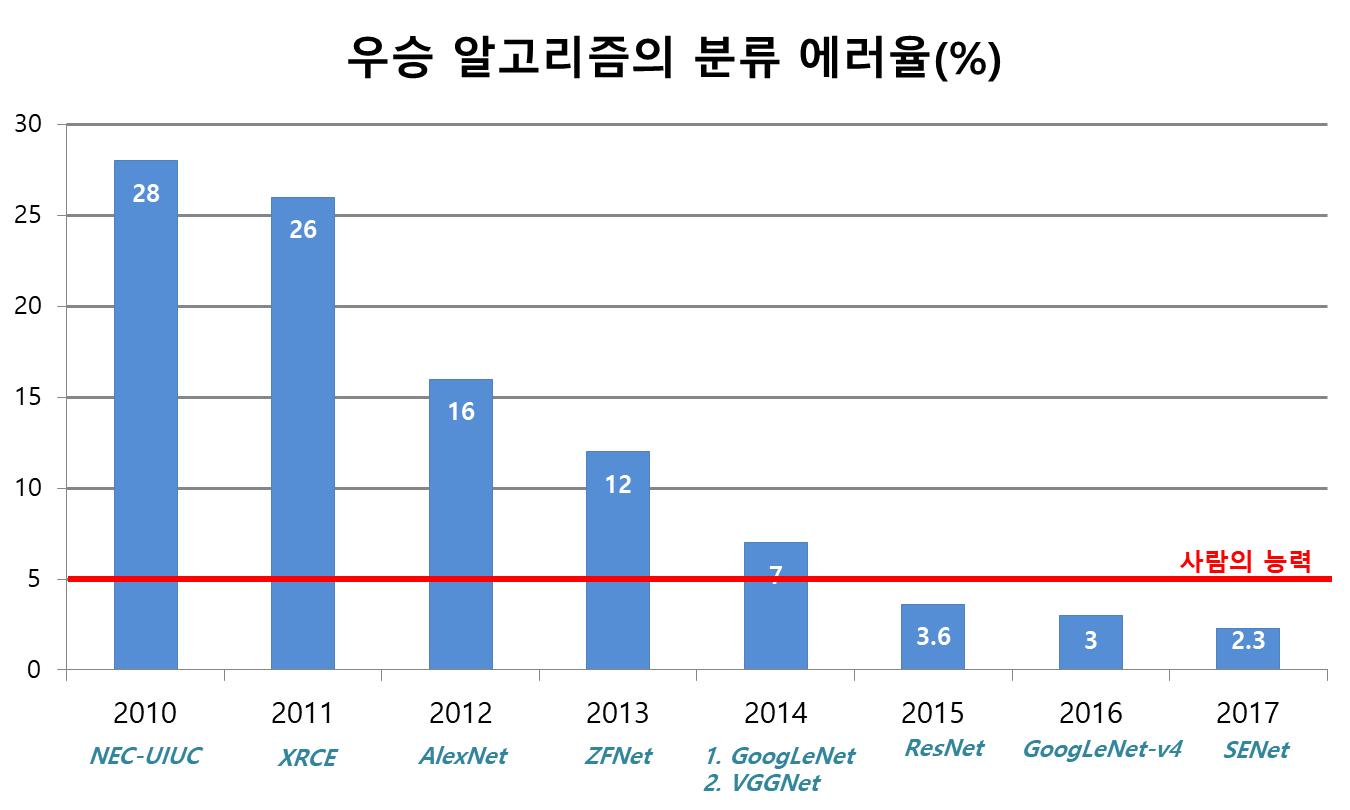
ZFNET : AlexNet을 기반으로 파라미터를 조절하여 성능을 끌어올린 모델
VGGNET : Layer가 많아서 깊어지면 성능이 좋다는 것을 이용한 모델로 filter의 사이즈는 줄이고 Layer를 깊게 쌓아 성능을 올린 것이 핵심이다. 이 때 3x3 conv연산을 3번연속 하는것은 7x7 conv연산을 한번하는것과 같은 영역의 크기를 이용 할 수 있으며 더 적은 파라미터를 갖는 다는 이점이 있다. Layer를 더 깊게 쌓아 성능을 올린다는 것은 Layer연산시 non-linearity가 더 많아지기 때문에 성능을 올릴 수 있다는 것이다.
⇒ 단순히 Layer가 많아 진다고 해서 성능이 올라갈 것이라고 생각하지 못하였다. 중요한것은 Layer의 양보다 질이라고 생각했기 때문이다 . 그러나 Layer가 많아지면 non-linearity 가 많아지기 때문에 성능이 좋아진다는 것을 이해 할 수 있었다. 그러나 이것에도 한계가 있었다.
GoogLeNet: MultiLayer Perceptron(MLP), Global Average Pooling(GAP), 1x1 Convolution Layer 등의 트릭이 매우 좋은 결과를 냈고 추후 모델들이 이러한 기법을 차용하였다. ⇒ 이 모델에서 사용된 수많은 기법들이 매우 흥미로움
- Inception : 이전 CNN모델들은 같은 Layer층에서 동일한 사이즈의 필터로 Conv연산을 했으나 GoogLeNet에서는 필터 사이즈가 다른 Conv연산 결과를 쌓아 올린 방식이다. 이전의 CNN모델의 Layer에서 Conv 연산이라고 하면 동등한 filter사이즈의 ConV로 아래와 같이 많은 파라미터와 계산량이 필요해진다.
- ConV Layer 계산
- 용어 정리 Input(입력데이터) : Height * Width * Channel Stride : 필터이동 보폭 pad : 가장자리 처리 사이즈 Filter : Height * Width (보통 채널은 제외하고 주어짐) parameters : 필터에 들어가는 값 + 각 필터의 bias
- **계산
GoogLeNet에서는 한 Layer의 filter 사이즈를 다르게 하여 ConV을 수행하고 쌓아 올리는 방식을 채택하였고 이에 따라 기존의 CNN모델들보다 더욱 다양한 특성을 도출해 낼 수 있었다. 그러나 GoogLeNet은 필터 사이즈를 다르게 ConV 연산을 함과 동시에 파라미터의 수를 줄일 수 있도록 차원을 줄이는 1x1 ConV을 실행하였다.
- ConV Layer 계산
- Global average pooling : 채널들의 평균을 원소로하는 1차원 벡터로 만듦 ⇒ 최종 classifier시 FC Layer 사용시 파라미터의 수가 매우 많아(연산효율, 오버피팅의 문제) 비효율적인 단점을 보완하였고, 기존의 FC방식은 입력데이터 (이미지)의 사이즈를 FC Layer 사이즈와 동일 하여야 했지만 GAP사용으로 인해 이미지의 사이즈가 자유로워 질수 있다.
- auxiliary classifier : 깊은 Layer로 때문에 학습에 따라 역 전파시 gradient가 0에 가까워 지면 학습이 이루어지지 않는 vanishing gradient 문제가 발생하는데 이것을 학습시에 auxiliary classifier를 이용하여 해결하는 방법이 사용되었다.
ResNet : Residual learning으로 잔차를 학습시키는 것에 아이디어를 둠, Layer가 깊어져 그래디언트가 0 이되어 학습 잘 이루어지지 않는 경우 Layer를 skip할 수 있음.
object detection : classification + localization으로 한 이미지에서 객체의 분류와 동시에 위치를 잡아냄
instance segmentation : OD에 mask를 추가하여 박스형태가아닌 객체의 크기에 맞춰 segmentation도 추가됨
R-CNN
Object detection 가장 기본 R-CNN은 object의 위치를 윈도우 형태로 임의로 뽑아 내는 연산을 Region Propsals을 수행한다. 그리고 뽑아낸 임시 객체의 윈도우를 각각 독립적으로 ConVNet을 수행하여 객체들을 분류하여 최종적으로 Object detection을 수행하게 된다.
Fast R-CNN
Region Propsals 함수를 이용하여 임시 객체의 윈도우들을 각각 독립적으로 ConVNet을 수행하게되면 연산량이 매우많아 속도가 느리다는 단점이 있었다. 따라서 이미지전체를 ConVNet하여 얻어 낸 특정맵에 원본이미지에서 구한 객체의 윈도우를 매칭하여 Object detection을 수행한다. 이때 처리속도는 굉장히 빨라졌다는것을 알 수 있다.
Faster R-CNN
Fast R-CNN에서 연산속도의 대부분은 ConVNet을 통해서 분류하는 것이아닌 Region Propsals 함수를 수행하는 과정에 대부분의 시간이 소모되었다. 따라서 이 Region Propsals 를 수행하는 것도 딥러닝으로 처리하면 어떨까? 에서 시작되었다. 결과적으로 원본 이미지에 ConVNet을 통해서 얻어낸 특정 맵에 대해서 Region Propsal을 수행하는 네트워크를 통하여 ROI를 뽑아내는 작업과 분류하는 작업을 딥러닝을 통하여 동시에 병렬적으로 수행했더니 매우 빨라진 것을 확인 할 수 있었다. ⇒ 이 때 RPN의 입력 데이터는 원본 이미지가 아닌 ConVNet 연산을 수행한 특정 맵이라는 점이다. 또한 ROI를 추출하는 연산을 수행하고 난뒤 분류를 하는 것이아니라 동시에 병렬적으로 수행된다는 것에서 연산 속도가 매우 빨라졌다.
