인공지능응용시스템LS3
인하대학교 ICE4101 수업을 듣고 정리하였습니다.
잘못된 내용은 코멘트 부탁드립니다.
인공지능 응용시스템 Lecture Summary #3 12161783 전민규
인공지능 응용시스템 3번째 Lecture Summary
중간고사 이후 Deep Learning Tips, Generative Modeling, Temporal Modeling등 복잡한 경우를 다루었다. LS1과 LS2에서 전체적인 요약을 하였지만 이번 LS3에서는 Batch Normalization에 대해서 자세하게 다루었다. 이것은 2015년에 발표된 이후 딥러닝 성능 향상의 핵심적인 역할을 했다고 할 수 있으나 배치를 정규화 한다고해서 학습이 쉽고 빠르게 이루어 질 수 있다는 것에 의문을 품었었기 때문이다.
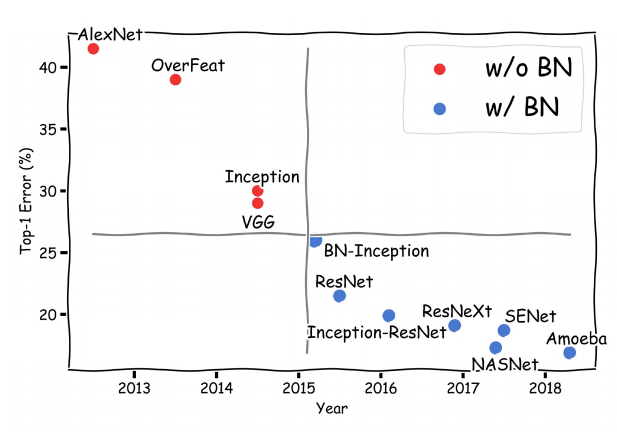
<2015년 Batch Normalization논문이 발표된 이후 성능향상 표>
Bias-Variance Tradeoff
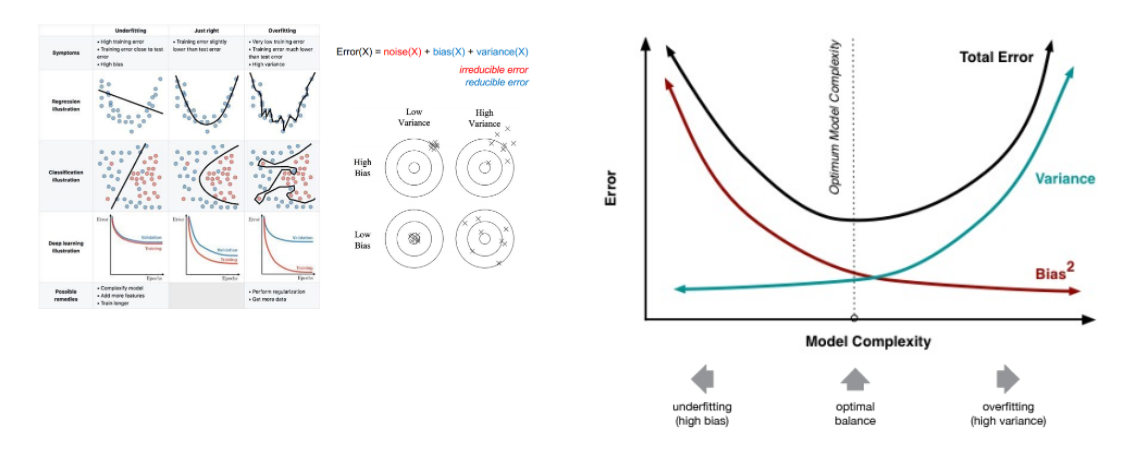
underfitting , overfitting의 예시 Variance는 같은 것끼리 얼마나 떨어져 있는가이고 Bias는 목표지점의 영점이라고 할 수 있다.
LowBias & LowBias가 이상적인 학습결과이며 High Variance는 오버피팅이고 High Bias는 언더피팅이다. Variance와 Bias가 동시에 낮은 error를 갖도록 조절해야한다.
- Early Stopping : Validation set loss가 꾸준히 증가하는 경우 학습을 더할필요가 없다는 것이다. 학습을 중단하고 가장 좋았을때의 W를 저장하고 테스트를 진행한다.
Mini-batch : 배치를 한번더 나눈것
미니배치를 사용함으로서 전체 training set의 derivative of loss w.r.t param을 근사할 수 있으며 병렬처리의 이득을 더 많이 볼 수 있다.
Batch Normalization : layer의 입력 데이터가 가지는 mean과 variance를 강제로 조작하여 일정한 destribution을 가지도록 하는 기법이다. 트레이닝을 쉽게하기 위한 방법으로 높은 learning rate로 굉장히 빠른 학습이 가능하다.
Batch Normalization 논문(Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe, Christian Szegedy)에 따르면
tranning시 불안정화가 발생하는 이유는 Internal Covariance Shift라고 적혀있다.
Internal Covariance shift는 layer 나 Activation를 통과할 때 마다 입력값의 Covariance가 달라지는 현상으로 이 현상은 훈련을 늦추고 낮은 학습률의 결과를 나타낸다고 한다. 따라서 Batch Normalization을 수행하는 layer를 추가로 layer에 대한 입력을 정규화 함으로서 문제를 해결한다고 주장한다.
아래는 MNIST에서 Batch Normalization을 추가한 실험의 결과이다
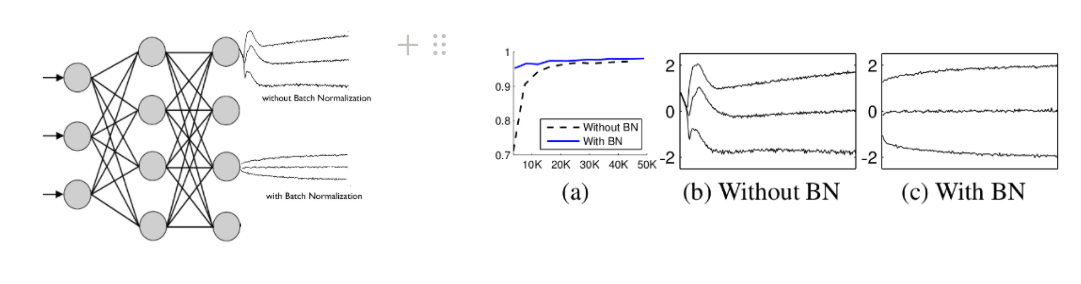
Batch Normalization는 layer사이에 두어 Covariance shift가 발생하지 않도록 평균과 분산 조정을 별도의 과정으로 진행하지 않고 Network안에서 학습 시 동시에 조절하는 것이다.

각각 채널별로 독립적으로 수행하며 이 때 e는 x가 발산하는 것을 방지하기 위해 학습에 영향을 주지않는 작은 값이다.
일반적으로 FC layer다음 nonlinearity이전에 즉 둘 사이에 진행한다.
mini-batch의 평균과 분산을 이용하여 정규화를 진행하고 ( 이 때 모든 sum은 dimension끼리의 sum) , 학습가능한 파라미터 γ(감마)와 β(베타)를 이용하여 Batch Normalization의 최악의 상황에서 학습이 이루어지는 것을 막아 원상태로 학습시킬 수 있는 여지를 준다. (γ,β = scale & shift 파라미터) 즉, γ → σ , β → μ 인경우 원생태로 복귀된다.
또한 높은 Learning rate로 학습시 scale때문에 gradient가 vanish하거나 local minima에 빠지는 경우가 발생 할 수 있다. 그러나 Batch Normalization을 사용할 경우 propagation할 때 파라미터의 scale에 영향을 받지 않게 되므로 결과적으로 높은 Learning rate로 학습이 가능해진다.
또한 network가 가지고 있는 초기 파라미터와 무관하게 일정한 input variance로부터 gradient flow를 계산하므로 gradient flow의 성능을 향상시킨다.
오버피팅을 방지할 수 있는 regularization 효과가 있어 학습속도가 매우 느린 dropout기능을 대신하여 수행할 수 있는 가능성을 제시한다.
강제로 input의 destribution을 제한하기 때문에 saturating nonlinearity문제를 방지할 수있다.
트레이닝시 μ와 σ는 학습 가능한 파라미터로 두지만 테스트 시에는 트레이닝때 구한 μ와 σ의 각각 평균을 상수처럼 사용하여 테스트한다.
정리하자면 Batch Normalization은 일반적으로 FC와 nonlinearity layer 사이에 위치한다.
학습을 통해서 γ ,β 를 구하고 이것을 통해 원본상태로 갈수있는 여지를 준다.
장점 :
gradient의 scale이나 초기값에 대해서 dependency가 줄어들어 높은 Learning Rate를 줄 수 있기 때문에 결과적으로 빠른 학습이 가능하다
높은 Learning Rate를 줌으로서 발생하는 여러문제를 해결 할 수 있다.
오버피팅을 방지할 수 있는 regularization 효과가 있다.
정규화로 인해 다양한 하이퍼 파라미터에 대해서 덜 민감하게 작용 할 수 있다
맹점 :
비디오와 같이 데이터가 커서 작은 Batch사이즈의 경우 성능이 낮게 나올 수 있다.
